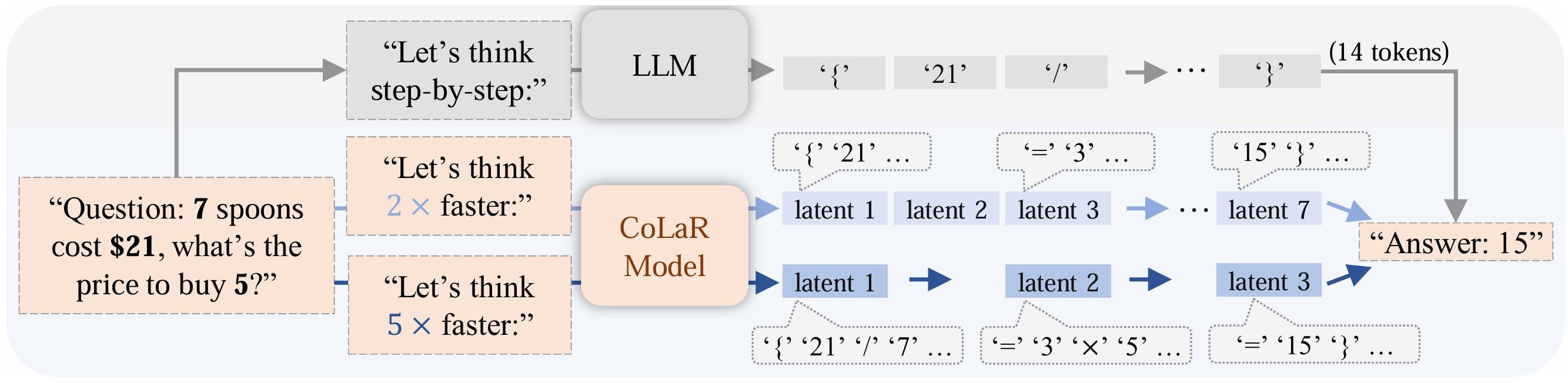
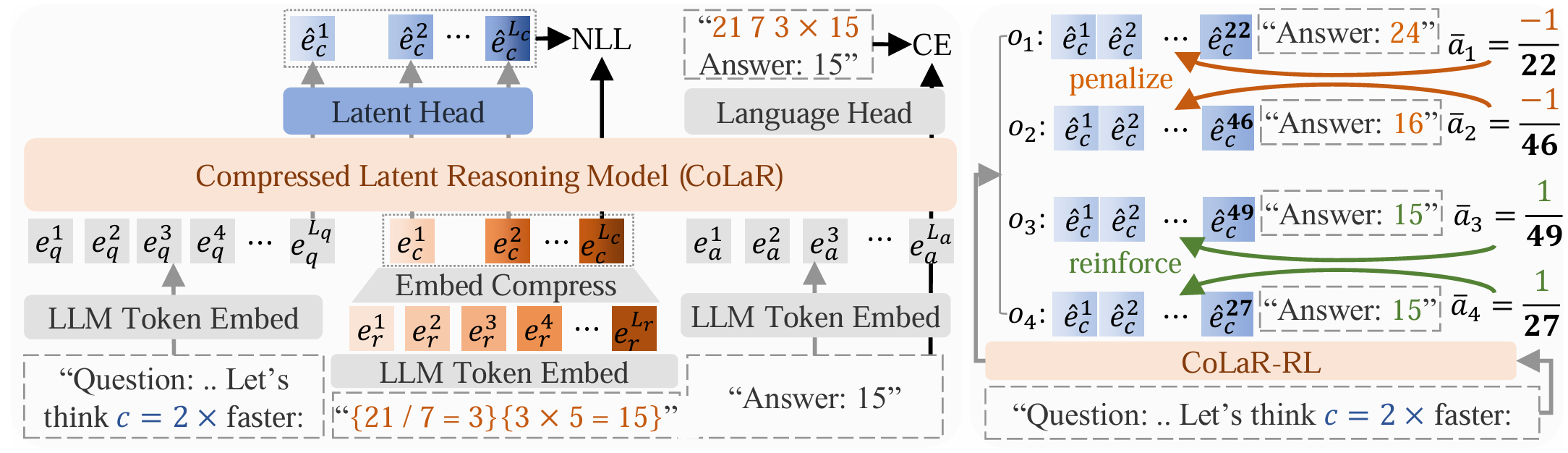
Our proposed method CoLaR consisting an LLM backbone and a Latent Head. During the \textbf{SFT stage (left)}, for each training step, CoLaR first compresses embeddings $\mathbf{e}_r$ of the original reasoning chain into compressed embeddings $\mathbf{e}_c$ with a compression factor $c$ randomly selected from the range $[1, c_{max}]$. Then, CoLaR is trained to predict: i) the compressed reasoning embeddings via the Latent Head, and ii) the compressed reasoning tokens and answer tokens through the Language Head. During the \textbf{RL stage (right)}, for every question input, CoLaR samples a group of $G$ outputs $o_{1:G}$ consisting of the latent reasoning chain and the predicted answer. We then calculate the relative rewards $a_{1:G}$ for each output, and the rewards are averaged on each token ($\bar{a}_i$), encouraging CoLaR to explore diverse latent reasoning pathways and exploit those more compact ones.
Given $\mathbf{t}, \mathbf{e}, \mathbf{h}$ denote tokens, embeddings, and hidden states, respectively, and subscripts $q, r, c, a$ denote question, reasoning chain, compressed (latent) reasoning chain, and answer, respectively,
The objective of SFT stage could be formulated as the sum of the following two losses (MathJax included):
$\mathcal{L}_{\text{comp}}=-\frac{1}{L_a+L_c}\sum_{i=1}^{L_a+L_c}\log p([\mathbf{t}_c,\mathbf{t}_a]^i|[\mathbf{e}_c, \mathbf{e}_a]^{1:i-1}, \mathbf{e}_q)$,
and
$\mathcal{L}_{\text{latent}}(i)= -\log p(e_c^i \mid \hat{\mu}_c^i, \hat{\sigma}_c^i) = \frac{(e_c^i - \hat{\mu}_c^i)^2}{2\hat{\sigma}_c^i} + \log \hat{\sigma}_c^i$.
The objective of RL stage could be formulated as:
$\mathcal{L}_{\text{GRPO}} = -\frac{1}{G}\sum_{i=1}^{G}\left(
\min \left(
\frac{\pi_{\theta}\left(o_i | q \right)}{\pi_{\theta_{\text{old}}}\left(o_i | q \right)}A_i,
\text{clip}\left(
\frac{\pi_{\theta}\left(o_i | q \right)}{\pi_{\theta_{\text{old}}}\left(o_i | q \right)},
1 - \epsilon,
1 + \epsilon
\right) A_i
\right)
\right)$.